
Data Virtualization vs ETL: Which Path is Right for Your Data?


If you work with data long enough, you eventually hit the same fork in the road: data virtualization vs ETL. One promises real‑time views across scattered systems; the other has powered data warehouses for decades. Both sound reasonable. Both have fans on your team. And your job is to choose a path without breaking reporting, compliance, or the budget.
This guide walks through what each approach really does, how they differ in practice, and a simple way to decide when to use ETL, when to use data virtualization, and when the smartest move is to use both together.
Table of Contents
- ETL vs data virtualization in 60 seconds
- What is ETL?
- What is data virtualization?
- Data virtualization vs ETL: key differences
- How to choose: 5 questions to ask
- Using data virtualization and ETL together
- Real‑world example: modernizing reporting
- FAQ: Common questions about ETL and data virtualization
ETL vs data virtualization in 60 seconds
Short version:
- ETL (Extract–Transform–Load) moves data out of source systems, transforms it, and loads it into a target store like a data warehouse or data lake for analytics (source: IBM ETL overview).
- Data virtualization leaves data in place and presents a virtual consolidated view across multiple sources, often in near real time (source: Wikipedia on data virtualization).
Use ETL when you need curated, historical, high‑performance datasets for heavy analytics, regulatory reporting, or complex transformations.
Use data virtualization when you need fast access to data spread across many systems, want to limit physical copies, or must respond quickly to new questions and data sources.
Most modern architectures use both: ETL for stable, governed data stores and data virtualization as a flexible “logical layer” on top, a pattern Cadeon implements often in data virtualization projects.
What is ETL?
ETL stands for Extract, Transform, Load — a long‑standing way to integrate data by copying it from source systems into a central store after cleaning and reshaping it (source: IBM ETL overview). Think of it as building a well‑organized warehouse: you pull goods from many suppliers, clean and label them, then store them neatly on shelves for later use.

How ETL works in practice
- Extract: Pull data from source systems (ERP, production databases, flat files, IoT feeds, etc.).
- Transform: Clean, standardize, join, and aggregate data to fit your target model.
- Load: Write the transformed data into a warehouse, mart, or lake where analytics tools can query it (source: Wikipedia on ETL).
Many of Cadeon’s clients still rely on ETL‑style data integration and consulting services for enterprise data warehouses and regulatory reporting.
Where ETL shines
- Stable reporting: Finance and regulatory teams need consistent, historical data that won’t change under their feet.
- Heavy transformations: Complex business rules, data quality checks, and aggregations are easier when data is physically reshaped and stored.
- Performance for big queries: Star schemas and columnar warehouses are built so BI tools can crunch large volumes quickly.
Where ETL hurts
- Latency: Batch loads often run nightly or hourly. If operations want near‑real‑time insight, that delay stings.
- Replication: Copying data into multiple warehouses and marts multiplies storage and governance work.
- Change cost: Adding a new column or source can mean updating multiple pipelines, tests, and models.
What is data virtualization?
Data virtualization is a data‑management approach that lets applications query and join data from many sources as if it lives in one place, without physically moving it (source: Wikipedia on data virtualization). The virtualization layer connects to sources, builds logical views, and exposes them to BI tools, APIs, or applications.
Instead of yet another warehouse, you gain a logical data layer that can sit on top of databases, warehouses, lakes, SaaS apps, and even streaming feeds. This is why analysts often talk about virtualization as a core component of a logical data warehouse.

Where data virtualization shines
- Near‑real‑time views: You query live or cached data from sources instead of waiting for the next ETL batch.
- Fast prototyping: New datasets can be joined and exposed quickly, without standing up new physical stores.
- Fewer copies: Central teams can govern access and definitions once, while data stays at the source.
- Self‑service: With the right catalog and tooling, business teams can discover and use curated virtual views more easily.
Limits of data virtualization
- Very heavy workloads: Long‑running, high‑volume transformations may still be better pushed into a warehouse or lake.
- Source dependency: Query performance and availability depend on underlying systems and network paths.
- Not a silver bullet: Bad source data remains bad; virtualization doesn’t magically fix quality or governance issues.
At Cadeon, we often implement data virtualization solutions as part of wider analytics programs, especially when clients want a single consistent view across many operational systems.
Data virtualization vs ETL: key differences that matter
On paper, etl vs data virtualization looks like a simple either/or choice. In reality, they solve different parts of the same problem: moving from messy, scattered data to usable, trusted insight.
From a modern architecture standpoint, ETL builds and feeds your physical warehouses and lakes, while data virtualization provides a logical layer to combine, secure, and deliver data across those stores and live sources. Gartner’s logical data warehouse model explicitly combines these two styles (see Gartner's logical data warehouse guidance).
How to choose: 5 questions to pick the right path
Instead of asking, “Is data virtualization better than ETL?”, ask these five questions. Your answers will usually point to the right mix of approaches.
1. How fresh does the data need to be?
- Sub‑hour or real‑time decisions? Data virtualization (and streaming) usually fits better.
- End‑of-day or weekly reports? ETL into a warehouse is often enough.
2. How stable are your requirements?
- If KPIs are well‑defined and change slowly, invest in solid ETL pipelines and curated models.
- If questions change every month, data virtualization helps you respond quickly without constant rebuilds.
3. What volumes and patterns do you expect?
- For massive aggregations (e.g., years of sensor or trading data), persisting data in a warehouse or lake is usually wiser.
- For lighter, user‑driven exploration across line‑of‑business systems, virtualization often offers a smoother experience.
4. What are your governance and compliance needs?
- ETL helps central teams enforce rules, data quality, and retention in a controlled store (source: Dataversity ETL overview).
- Data virtualization centralizes access control and lineage across many systems, reducing “shadow copies” and spreadsheets.
5. What skills and tools do you already have?
- If your team is deep in database engineering and existing ETL tools, you can evolve toward ELT in the warehouse and layer virtualization over time (source: Wikipedia on ELT).
- If you’re already using platforms like Spotfire with data virtualization capabilities, it may be simpler to start with virtualization and introduce targeted ETL where needed.
Using data virtualization and ETL together
In most Cadeon projects, data virtualization and ETL work side by side. A common pattern looks like this:
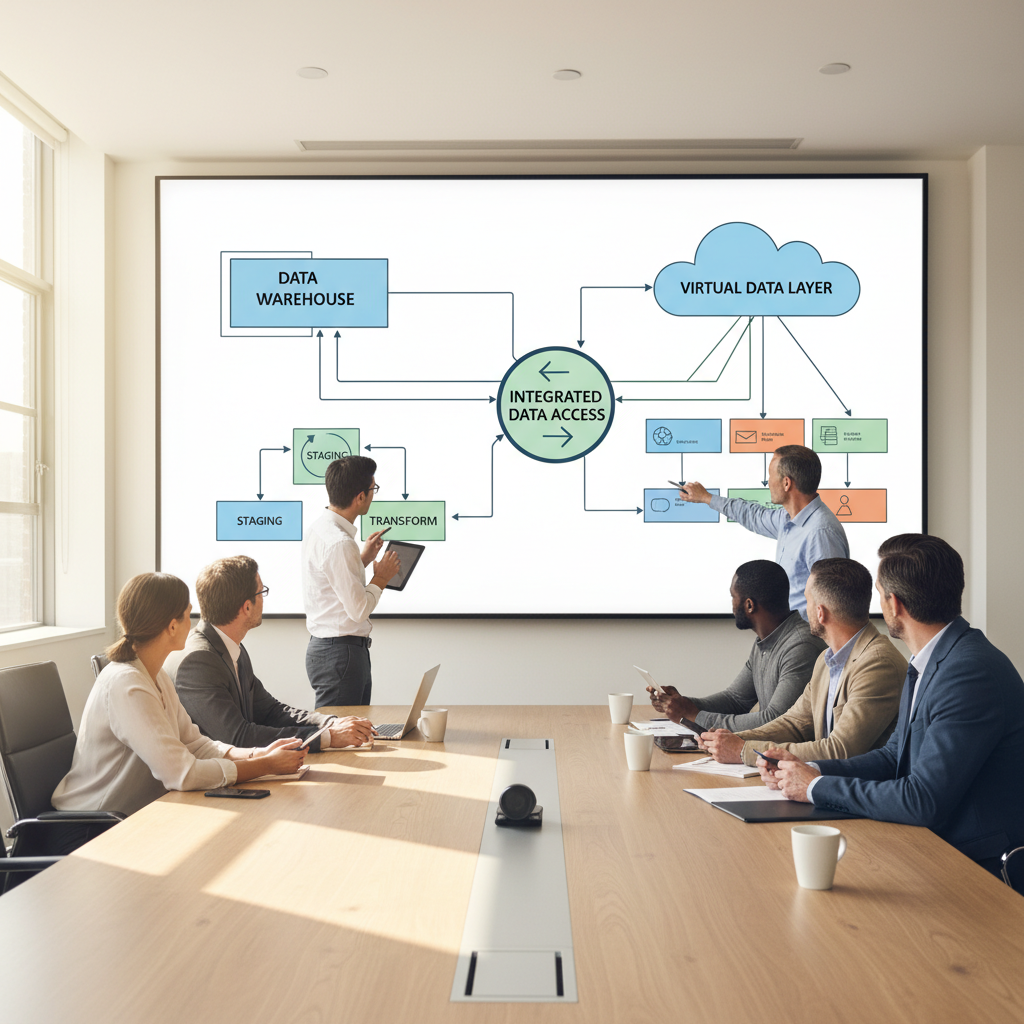
- Curated core via ETL: ETL/ELT pipelines feed a governed warehouse or lake with clean, historical data for finance, operations, and regulatory reporting.
- Virtual layer on top: A data virtualization platform connects to the warehouse, operational systems, and external feeds, exposing consistent, reusable views.
- Analytics and apps: Tools like Spotfire dashboards, self‑service BI, and data‑driven applications query those views instead of hitting every source directly.
This hybrid approach keeps the strengths of each: ETL for deep history and heavy lifting, data virtualization for agility and cross‑system visibility.
Real‑world example: modernizing reporting in an energy company
Here’s a familiar story for many energy and utilities teams.
A mid-sized operator pursuing Spotfire training had production, maintenance, and financial data scattered across legacy systems. Daily reporting still depended on spreadsheets, email attachments, and a fragile ETL job that loaded only a portion of the data into a warehouse overnight.
Working with Cadeon, they:
- Stabilized and simplified core ETL to create a trusted production and financial warehouse.
- Introduced a data virtualization layer to join live operational systems with the curated warehouse data.
- Exposed virtual views into Spotfire for operations and executive dashboards, with role‑based security applied once in the virtual layer.
The result: operations got fresher data and fewer extracts, finance kept their controlled numbers, and IT reduced the spread of one‑off data copies all without ripping out existing investments in ETL.
If that sounds close to home, you’re not alone; we cover similar patterns in our article on next‑gen data virtualization.
Next steps: pick a small, high‑value use case
If you’re still debating data virtualization vs ETL, take the same approach Cadeon uses with its partners: start small by selecting one reporting or analytics use case that creates the most friction today, then map which components require curated, historical data (strong fit for ETL) versus those that need fast, cross-system access (better suited for virtualization), so you’re making a practical, ROI-driven decision instead of overengineering the stack upfront.
Cadeon’s team has helped organizations across energy, utilities, finance, and other data‑intensive sectors make that call with measurable outcomes. If you’d like a second set of eyes on your architecture, you can book a free consult and explore what an incremental, low‑risk path could look like for your environment.
Key takeaway
Don’t think of “ETL vs data virtualization” as a winner‑takes‑all decision. ETL gives you stable, trusted datasets; data virtualization gives you speed and flexibility. The right strategy balances both so your teams spend less time hunting for data and more time using it.
FAQ: Common questions about data virtualization and ETL
How does ETL vs data virtualization affect security and governance?
ETL centralizes data into governed stores, which helps enforce standards but can multiply copies. Data virtualization centralizes access and definitions while leaving data in place, which can reduce sprawl. In practice, strong governance comes from combining both with clear ownership, data catalogs, and policies not from any single tool alone.
Can data virtualization handle large volumes and complex joins?
Yes, within reason. Enterprise‑grade platforms push work down to source systems, use caching, and support query optimization. That said, for extremely heavy workloads (petabyte‑scale history, intense aggregations), persisting data with ETL/ELT into a warehouse or lake is still the safer long‑term strategy (source: Wikipedia on data virtualization).
When should I choose ETL vs data virtualization for a new project?
A quick rule of thumb:
- Pick ETL‑first when you need stable, auditable, long‑term data for finance, regulatory, or heavy analytical workloads.
- Pick data virtualization‑first when your main pain is scattered data, many operational systems, and rapidly changing analytics questions.
In many cases, you’ll start with virtualization to prove value quickly, then formalize key datasets into a warehouse via ETL as they mature.
Is data virtualization replacing ETL?
No. Data virtualization and ETL solve different problems. ETL (and ELT) still underpins many data warehouses and lakes, while data virtualization offers a flexible logical layer on top. Most modern “data fabric” and logical data warehouse architectures deliberately combine both approaches (see this explanation of logical data warehouses).
Ready to transform your data strategy?
You might also like
.png)
AI As a Paradigm Shift
Here’s something our team has been talking about. If your organization is investing in AI—pilots, platforms, use cases—but somehow the results still feel incremental instead of transformative, then keep reading.
What Is Data Integration? Methods, Tools, and BI Explained
